원문 자료 : 딥러닝을 이용한 자연어 처리 입문 (링크: https://wikidocs.net/22886)
서문
앞서 배운 피드 포워드 신경망은 입력의 길이가 고정되어 있어 자연어 처리를 위한 신경망으로는 한계가 있었습니다. 결국 다양한 길이의 입력 시퀀스를 처리할 수 있는 인공 신경망이 필요하게 되었는데, 자연어 처리에 대표적으로 사용되는 인공 신경망이 바로 순환 신경망(Recurrent Neural Network, RNN)입니다. 이번 챕터에서는 가장 기본적인 순환 신경망인 바닐라 RNN, 이를 개선한 LSTM, GRU에 대해서 학습해봅시다. LSTM과 GRU를 이해한다면 텍스트 분류나 기계 번역과 같은 다양한 자연어 처리 문제들을 풀 수 있습니다.
다양한 길이의 입력 시퀀스를 처리하기 위해 RNN고안.
하지만 RNN에서도 단점을 보완한 점이 LSTM 및 GRU.
내용
RNN(Recurrent Neural Network)은 순환 신경망이라고도 하며, 시퀀스 데이터를 처리하기 위해 설계된 딥러닝 모델이다.
(이름에서 알 수 있듯이 'recurrent'는 '반복되는'이라는 의미.)
RNN의 핵심 특징은 입력 데이터의 순서를 고려할 수 있다는 점.
=> 이는 시계열 데이터, 텍스트, 음성 인식 등 시간에 따라 변화하는 데이터를 다루는 데 유리함
입력과 출력을 시퀀스 단위로 처리
(*시퀀스는 문장과 같은 단어가 나열된 것을 의미)
이러한 시퀀스를 처리하기 위해 만든 시퀀스 모델 중 딥러닝의 가장 기본적인 시퀀스 모델.
TMI(or TIP) : 용어는 비슷하지만 순환 신경망과 재귀 신경망(Recursive Neural Network)은 전혀 다른 개념
앞서 배운 것들은 은닉층에서 활성화 함수(activation function)를 지닌 값은 오직 출력층 방향으로만 향함.
-> 이와 같은 애들을 피드 포워드 신경망(Feed Forward). 개인적인 생각으론 앞방향으로 '먹인다'는 것이 잘 표현한듯.
=> 하지마 RNN은 은닉층 노드에서 활성화 함수를 통해 나온 result를 출력층 방향으로도 보내지만 다시 은닉층 노드의 입력으로도 보냄
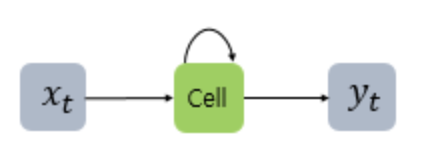
위 그림서 x는 입력층의 벡터, y는 출력층의 출력 벡터이다. (bias 또한 입력으로 존재할 수 있지만 위 그림에선 생략)
- 셀(cell) : RNN에서 은닉층에서 활성화 함수를 통해 결과를 내보내는 역할을 하는 노드
이 셀은 이전 값을 기억하려고 하는 (일종의 메모리 역할) -> 이를 메모리 셀 or RNN 셀 이라고 표현
은닉 층의 메모리 셀은 각각의 시점에서 바로 이전 시점에서의 은닉층의 메모리 셀에서 나온 값을 자신의 입력으로 사용하는 재귀적 활동을 함. 현재 시점 t에서 메모리 셀이 다음 시점인 t+1의 자신에게 보내는 값을 은닉 상태(hidden state)라고 함.
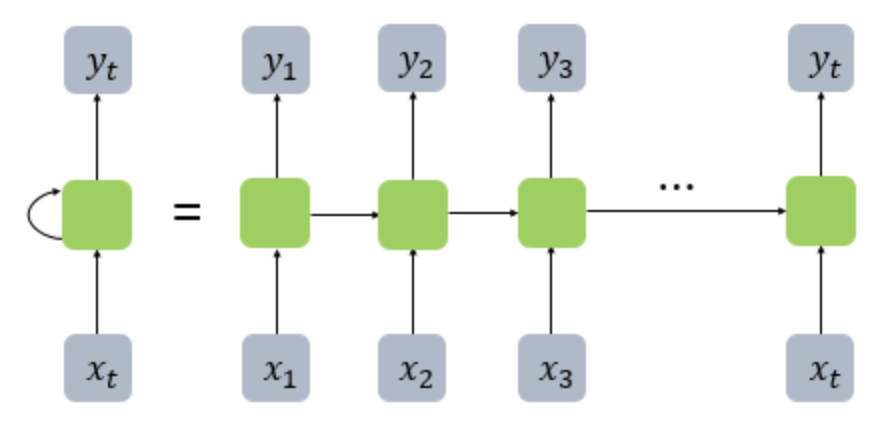
해당 내용을 그림으로 표현하면 다음과 같음.
(좌측 사진은 화살표로 사이클을 그려 재귀 표현, 우측은 여러 시점으로 펼쳐서 표현)
Feed Forward 신경망에서는 뉴런이라는 단위를 사용했지만, RNN에서는 입력 벡터, 출력 벡터, 은닉층에서는 은닉 상태라는 표현을 주로 더 사용.
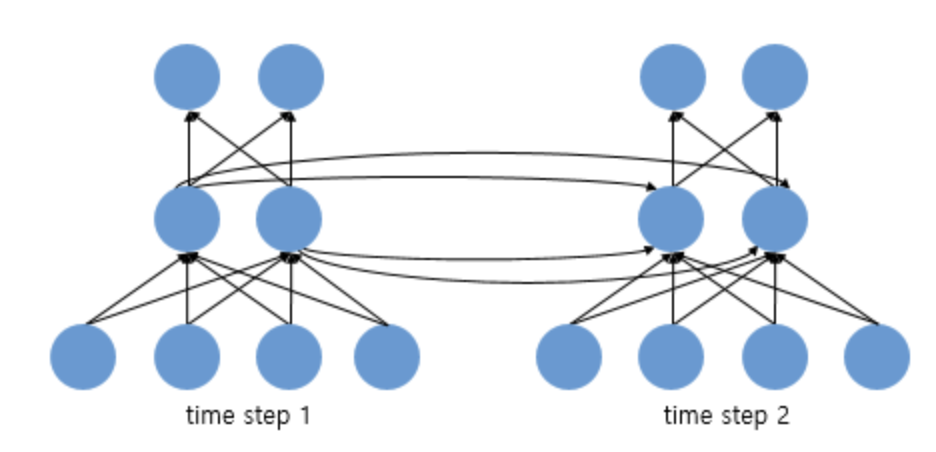
이를 뉴런 단위로 시각화 한다면 다음과 같고, 뉴런 단위로 해석 시 입력층의 뉴런 수는 4, 은닉 층의 뉴런 수는 2, 출력층의 뉴런 수는 2.
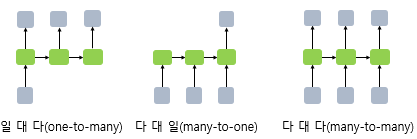
RNN은 입력과 출력의 길이를 다르게 설계 가능. (입, 출력의 단위는 정의하기 나름이지만 가장 보편적인 단위는 '단어 벡터')
--- 24년 10월 5일. (08-01 보충 필요)
바닐라 RNN의 한계
(앞서 배운 가장 단순한 형태의 RNN을 Vanila RNN이라 한다. 바닐라 RNN의 한계를 극복하기 위해 나온 다양한 RNN의 변형 중 LSTM에 대한 소개.)
바닐라 RNN은 출력 결과가 이전의 계산 결과에 의존. 하지만 비교적 짧은 시퀀스에 대해서만 효과를 보임.
(어쩌면 가장 중요한 정보가 시점의 앞 쪽에 위치할 수 있음.)
=> 이 문제를 장기 의존성 문제(The problem of Long-Term Dependencies)라고 함.


바닐라 RNN은 x_t와 h_t-1이라는 두 입력이 (가중치가 곱해져) 메모리 셀의 입력이 됨.
-> 이를 hyperbolic tangent의 입력으로 사용. -> 이 값은 은닉층의 출력인 은닉 상태가 됨.
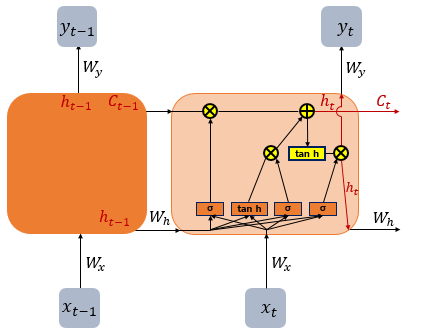
--- 24년 10월 6일. (08-02 추가 필요)
주요 특징
- 순환 구조: RNN은 시퀀스의 각 항목을 처리할 때, 이전의 항목에서 얻은 정보를 현재 항목의 계산에 활용할 수 있도록 설계되어 있습니다. 이 때문에 RNN은 현재 시점의 입력뿐만 아니라 이전 시점의 입력도 기억하고 활용할 수 있습니다.
- 상태 유지: RNN의 각 노드는 현재 시점의 입력과 이전 시점의 은닉 상태(hidden state)를 결합하여 새로운 은닉 상태를 만듭니다. 이 과정에서 이전의 정보가 지속적으로 전달되므로, 모델이 순차적인 정보를 처리하고 학습하는 데 도움을 줍니다.
한계와 문제점
- 기울기 소실/폭발 문제: RNN은 긴 시퀀스를 처리할 때, 역전파 과정에서 기울기(gradient)가 소실되거나 폭발하는 문제가 발생할 수 있습니다. 이는 RNN이 긴 시퀀스에서 장기 의존성을 학습하는 데 어려움을 겪게 만듭니다.
- 단기 기억 문제: RNN은 상대적으로 짧은 시퀀스에서 잘 동작하지만, 시퀀스가 길어질수록 이전 정보가 사라지기 쉬워 장기 의존성(long-term dependency)을 학습하는 데 어려움이 있습니다.
LSTM과 GRU
RNN의 위 한계를 극복하기 위해 RNN의 변형 모델인 LSTM(Long Short-Term Memory)과 GRU(Gated Recurrent Unit) 등이 개발되었으며 이들 모델은 내부 게이트 구조를 통해 기억과 잊기의 과정을 조절함으로써 장기 의존성을 더 잘 학습할 수 있음.
RNN은 자연어 처리, 음성 인식, 기계 번역 등 다양한 시퀀스 처리 작업에 사용되었으며, 여전히 일부 응용 분야에서 중요한 역할을 하고 있습니다. 하지만, 현재는 트랜스포머(Transformer)와 같은 모델이 더 널리 사용되고 있습니다.
참고
https://casa-de-feel.tistory.com/39
'ML & AI > Pytorch' 카테고리의 다른 글
| [PyTorch] MNIST 손글씨 분류 실습 (3) | 2024.10.26 |
|---|---|
| [Pytorch로 시작하는 딥 러닝 입문] 3. 머신 러닝 입문하기(Machine Learning Basics) (0) | 2024.09.21 |
| [Pytorch로 시작하는 딥 러닝 입문] 2. 파이토치 기초(PyTorch Basic) (4) | 2024.09.21 |
| [Pytorch로 시작하는 딥 러닝 입문] 1. 시작 & 딥 러닝을 시작하기 전에 (1) | 2024.09.18 |