[Pytorch로 시작하는 딥 러닝 입문] 1. 시작 & 딥 러닝을 시작하기 전에

참고 자료
https://wikidocs.net/book/2788
Pytorch로 시작하는 딥 러닝 입문
이 책은 딥 러닝 프레임워크 `PyTorch`와 허깅페이스의 `Transformers`를 사용하여 딥 러닝에 입문하는 것을 목표로 합니다. **AI의 완전 쌩 입문자**…
wikidocs.net
본 카테고리는 해당 책의 wikidocs 기준으로 만들어졌다.
기존에 알고 있던 Pytorch에 대해 다시 한 번 기초를 재정립할 겸 이 책을 기준으로 정리하고자 한다.
깃허브 주소: https://github.com/ukairia777/pytorch-nlp-tutorial
GitHub - ukairia777/pytorch-nlp-tutorial: pytorch를 사용하여 텍스트 전처리부터, BERT, GPT와 같은 모델의 다
pytorch를 사용하여 텍스트 전처리부터, BERT, GPT와 같은 모델의 다운스트림 태스크들을 정리한 Deep Learning NLP 저장소입니다. - ukairia777/pytorch-nlp-tutorial
github.com
01-01 코랩(Colab)과 아나콘다
우선 아나콘다부터 설치를 해준다. 다만, 본 책은 Window기준으로 설치를 진행하고 있기에 Mac(M2)의 설치 방법을 찾아 그대로 따라준다.

아나콘다를 설치하는 주요 이유는 다음과 같다. (GPT Thank you)
- 패키지 관리 및 의존성 해결: 아나콘다는 Conda라는 패키지 관리 도구를 제공하여 파이썬 패키지의 설치 및 의존성을 쉽게 관리할 수 있습니다. 특히, 여러 패키지가 서로 다른 버전을 요구하는 상황에서 환경을 분리하여 문제를 방지할 수 있습니다.
- 가상 환경 관리: Conda는 가상 환경을 쉽게 만들고 관리할 수 있는 도구로, 프로젝트마다 별도의 환경을 설정하여 서로 다른 버전의 파이썬이나 패키지를 사용할 수 있게 해줍니다.
- 다양한 과학 및 데이터 분석 패키지 기본 제공: 아나콘다는 데이터 과학, 기계 학습, 통계 분석에 자주 사용되는 패키지들(예: NumPy, Pandas, Matplotlib, Scikit-learn, TensorFlow 등)을 기본적으로 포함하고 있어 따로 설치할 필요가 없습니다.
- 편리한 설치: 아나콘다는 파이썬과 다양한 패키지를 한 번에 설치할 수 있는 통합 환경을 제공합니다. 이를 통해 초보자들도 번거로움 없이 필요한 도구를 빠르게 설치하고 사용할 수 있습니다.
- Jupyter Notebook 통합: 아나콘다에는 Jupyter Notebook이 포함되어 있어 데이터 분석 및 학습 과정에서 매우 유용합니다. 이를 통해 코드를 실시간으로 실행하고 시각화할 수 있습니다.

설치 완료 후 terminal 오픈 시 다음과 같이 (base)가 앞에 붙어있으며 conda에 대한 command를 확인하였을 때 잘 나오는 것을 볼 수 있다.
> conda update -n base conda
> conda update --all의 명령어로 모든 파이썬 패키지들을 업데이트 해준다. Proceed [Y/N] 나오는 경우는 Y 후 엔터를 쳐주자.
Colaboratory
Colab 주소 : https://colab.research.google.com/
-> 학교 이메일 계정으로 만들었다가 별도의 이점은 없는 것 같아 개인 계정으로 재생성.

CPU에서 GPU로 런타임 유형 변경을 하려는데 TPU가 존재하여 찾아보니 TPU가 더 맞을 것 같아 TPU로 설정하였다.
(추후 여러 코드를 번갈아 돌려가보며 테스트 진행해보고자한다.)
참고 링크 : https://8terabyte.com/7#google_vignette

머신 러닝 워크 플로우(Machine Learning Workflow)

1. 수집
데이터 수집에 있어 어떤 데이터를 수집할 것인지, 어느 범위까지 수집할 것인지 생각해야한다.
DSP 입장에서는 어떤 소스를 통해 (ex. from DMP인지 어느 bundle들로부터 데이터를 가져올 것인지, 그 외의 검색 데이터, 혹은 행동 데이터를 가져올 것인지) 데이터를 수집할 지 결정하여야한다.
개인적인 생각으론 수집 단계에선 최대한 많은 데이터를 가져오는 것이 중요하지 않을까 생각한다. 어차피 후의 전처리 및 정제 단계에서 무의미한 데이터들이라면 줄이면 되기 때문이고, 모델링 단계에서 feature 및 factor의 수를 줄이며 연산을 최적화 하고자 하려하기 때문이다.
2. 점검 및 탐색
데이터들의 어떤 구조를 띄고 있는지, 데이터의 특징 파악 단계이다.
3. 전처리 및 정제
DA로 일을 하며 이 부분이 가장 어렵지 않나 라고 생각된다. 주관적이면서도 객관적이게 데이터를 정제하며 남들을 설득시킬 수 있어야하고 이 부분에서 얼마나 전처리가 잘 되었는 지가 추후 Model의 성능을 결정하기도 하기 때문이다.
또한 Outlier들에 대한 처리를 무조건적으로 제거하는 것이 아닌 각 상황에 따라 알맞게 통제해야 더 좋은 insight를 얻을 수 있다.
4. 모델링 및 훈련
모델을 만든 후 Train / Test set을 구분하여 훈련시키거나 hyperparameter에 대한 조정이 필요하면 Validation set 또한 만들어 훈련을 진행하곤 한다. 항상 Overfitting과 Bias에 주의하자.
5. 평가
완성된 모델을 평가한다.
6. 배포
모델이 성공적이라 판단되면 배포한다.
Pandas, Numpy, Matplotlib
pandas
주로 사용하는 데이터 타입은 Dataframe과 Series이다.
numpy
list와 비슷한 구조를 가지지만 더 빠른 연산과 차이점이 조금 있다.
matplotlib
시각화 툴이다. seaborn까지 같이 이용하면 더 아름다운 시각화를 할 수 있다.
위 내용들은 이미 잘 알고 있는 부분이라 넘어간다.
01-05 데이터의 분리(Splitting Data)
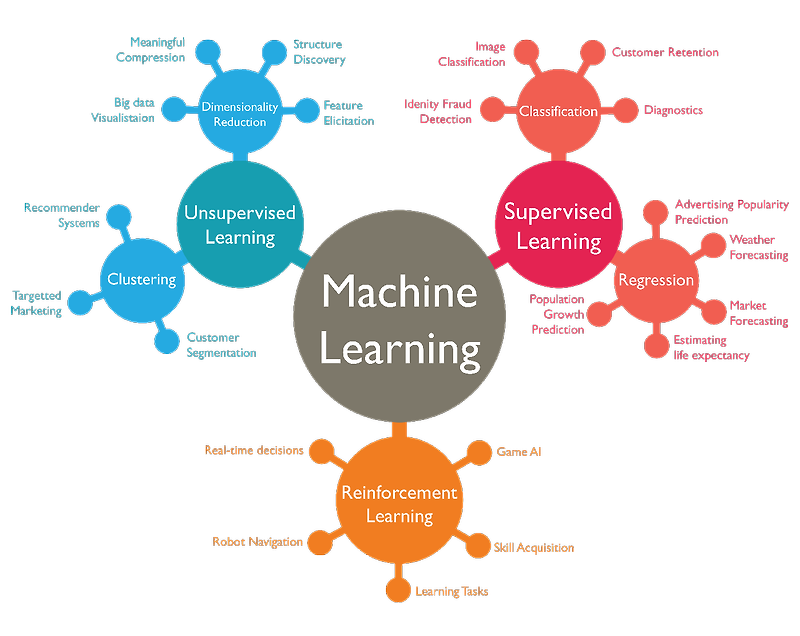
학습의 종류에는 크게 세 종류가 있다.
1. 지도 학습(Supervised Learning), 2. 비지도 학습(Unsupervised Learning), 3. 강화 학습(Reinforcement Learning)
다만, 이 책에서는 대부분 지도 학습(Supervised Learning)에 대해 배울 예정이다.
지도 학습은 라벨링된 정답이 있는 데이터를 학습 시킨다.
그럼 정답이 있는 데이터들을 모두 학습 시키는 것이 아닌 일부는 훈련(train)에 사용, 일부는 테스트(test)에 사용한다.
보통 7:3이나 8:2로 진행하는 것 같다.
위 작업을 진행하기 위해서는 데이터를 나눠야하는데 pandas의 Dataframe을 이용할 수도 있고, numpy를 이용할 수도 있다.
다만, scikit-learn을 사용하는 것이 조금 더 편해보인다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.2, random_state=1234)다음과 같은 코드로 분리를 할 수 있다.
test_size는 해당 데이터 중 test set의 비율을 얼마나 할 것인지 정하는 param이다.
위 0.2는 20%를 test size로 사용하겠다는 의미이다.
random_state는 랜덤으로 데이터를 분할할 때의 시드값이다.
이를 지정하지 않으면 위 코드를 돌릴때마다 다르게 분리가 된다. 하지만 특정 값을 사용하면 계속하여 동일하게 분리된 set들을 얻을 수 있다.